
Die Technik hinter dem Türschloss
Die Idee unseres Projekts ist es, das elektronische Türschloss des Computerraums wieder in Gang zu setzen und eine funktionierende Benutzerverwaltung und ein umfassendes Log-System einzubringen. Die Grundfunktionalität des Türschlossöffnens haben wir bereits in einem früheren Projekt umgesetzt, aber aufgrund von technischen Änderungen mussten wir dieses System noch einmal neu gestalten.
Anforderungen und Design
Angefangen haben wir damit, uns Gedanken zu machen, was für Funktionen unsere Software braucht, um im Alltag eingesetzt werden zu können. Im Fachjargon nennt man eine Software welche bestimmte Grundanforderungen erfüllt, MVP(minimum viable product). Dabei gab es nach unserem ersten Prototypen die Idee, abzuspeichern, wer wann das Schloss geöffnet hat, um möglichen Missbrauch zu verhindern. Dabei wurde uns klar, dass wir einen Unterschied zwischen regulären Benutzern und Administratoren machen müssen, damit die Daten nicht öffentlich verfügbar sind. Das brachte uns dann zur nächsten Funktion unserer Anwendung: der Nutzerverwaltung. Wir brauchten ein System, mit dem Administratoren Nutzer verwalten können. Die grundlegenden Funktionen waren für uns:
- Nutzer hinzufügen - auch direkt als Admin
- Nutzer löschen
- Die Rolle eines Nutzers ändern
- Passwörter von Nutzern zurücksetzen
Danach haben wir angefangen, das Interface der Website zu designen und zu Skizzieren, ganz altmodisch auf Papier:

Es fehlt noch das Designkonzept der Nutzerverwaltung, aber ansonsten ist der Grundaufbau erhalten geblieben. Der nächste Schritt für uns war es dann das Handgezeichnete ins Digitale zu übertragen. Dafür haben wir uns für das kostenlose Designprogramm Figma entschieden, da wir schon vorher mit der Software gearbeitet haben. Unser finales, digitales Design ist dabei stark von der Brutalismusbewegung im Webdesign inspieriert. Bekannt aus der Architektur liegt der Fokus im brutalistischen Webdesign auf purer Funktionalität sowie rohen Formen und Farben. Ganz gut beschreibt diesen Trend das folgende Zitat:
Harsh, stripped-down designs that have no frills, as a reaction to the cleanliness and polish of design systems. - uxbrutalism.com
Gute Beispiele dafür lassen sich auf brutalistwebsites.com finden:

Davon inspiriert haben wir unser Konzept designt:

Symmetrie, und einfache Formen und Farben waren uns besonders wichtig, um die Nutzerinteraktion so reibungslos wie möglich zu gestalten. Deswegen haben wir uns auch für die bildschirmfüllenden Eingabebereiche und Buttons entschieden, sowohl für die fette sans-serif Schriftart Poppins, welche sich an der Schriftart Futura orientiert, die zur Zeit des Bauhausdesigns entstand und aufgrund ihrer harten Kanten und klaren formen später brutalistische Architektur und Kunst prägte. Auch bereits sichtbar ist der Flow der Anwendung, hier durch Pfeile zu sehen. Der ist noch relativ simplistisch und eindimensional, wird aber noch wichtig wenn es später um das Programmieren der Website geht.
Die technische Umsetzung
Wir haben uns dazu entschlossen, das Türschloss in drei Teile zu spalten:
- Eine Backend API
- Die Website als Frontend
- Das Türschloss als Client der API, installiert auf dem Raspberry Pi
Diese Entscheidung hat sich im Endeffekt als sehr vorteilhaft erwiesen, da es uns ermöglichte, einzelne Teile der Anwendung separat zu entwickeln und später mit einander zu verknüpfen. Die Idee einer Aufteilung war schon im vorherigen Prototypen vorhanden, doch diese haben wir durch die Abspaltung des Frontends noch optimiert. Das hast mehrere Gründe:
Das Türschloss als Client der API zu designen basiert hauptsächlich auf dem Problem der Erreichbarkeit des RaspberryPi’s im Schulnetzwerk. Um von außerhalb des Netzwerks zuzugreifen bräuchten wir eine festgelegte Adresse über Iserv. Herr Laudien hat uns darauf aufmerksam gemacht, dass dieser Prozess über die Iserv Zentrale geschehen müsste, und möglicherweise überaus langwierig sein könnte. Deshalb haben wir uns für die Rapunzel-Strategie entschieden: Anstatt zu versuchen den Turm zu erklimmen, in unserem Fall die Firewall des HGO’s, lassen wir unseren Pi sein Haar hinunterlassen. Dafür verwenden wir eine relativ neue Technologie, genannt WebSockets. Diese ermöglicht es uns, vom Pi aus eine Verbindung zu unserem API Server aufzubauen, als würde man eine Website öffnen, doch diese Verbindung wird nicht wie im HTTP-Protokoll nach Abschluss der Übertragung geschlossen, sondern bleibt geöffnet. Das sorgt dafür, dass sich Server und Client gegenseitig Pakete senden können, die dann in unserem Fall z.B. das Türschloss öffnen.
Ein weiterer Grund für die Separierung war die Technologie, mit der wir das Frontend entwickelt haben. Um unsere Website so effizient wie möglich zu entwickeln, benutzen wir das Webframework Vue.js. Dieses ermöglich uns die Verwendung von Komponenten in unserer Anwendung, eine schnellere Interaktion mit der HTML-Seite, vereinfachte Listendarstellung, automatische Kompilierung von Vue Code in HTML, CSS und JS, was für kleinere Dateien sorgt, live-reload bei Codeänderungen und noch viel mehr. Dann können wir diesen kompilierten Dateien auf den Server übertragen, der diese dann anzeigt. Dabei erfolgt jede Kommunikation von Website und Server nur über die API. Im späteren Teil wird auf die einzelnen Aspekte noch im Detail eingegangen.
Das Backend
Wir haben uns im Backend als Programmiersprache für JavaScript entschieden, vor allem aufgrund unserer vorhanden Erfahrung in der Webanwendungsentwicklung darin. Um JavaScript ohne einen Browser auszuführen, benutzen wir die NodeJS runtime, welche die V8 Engine aus dem Google Chrome Browser verwendet. Daraus resultiert eine hohe Geschwindigkeit, da die V8 Engine für die Verwendung im Browser konzipiert wurde, welche besonders für langsamere Rechner und Mobilgeräte optimiert wurde, und durch JavaScripts Asynchronität wenige Resourcen bei Inaktivität verwendet. Um als Webserver zu fungieren benötigen wir das Framework Express. Damit können wir Routen einrichten, die entscheiden, welche Funktion bei einer Anfrage verantwortlich ist, und bei diesen mit Dateien, Text oder JSON antworten. Außerdem macht Express das Aufspalten der Routen in Module möglich, die ähnlich wie Klassen in Java dynamisch geladen und wiederverwendet werden können. Der Pfad für unsere API sieht damit nach mehreren Revisionen so aus:

Das sind alle Routen auf die vom Server verfügbar sind. Wie man sehen kann funktionieren diese Routen nach einfacher Vererbung, welche zum einen durch die Anfrage-URL und zum anderen durch die Art der Anfrage unterteilt wird. Nehmen wir zum Beispiel eine Anfrage auf “/api/user”, und da die API nach REST Prinzipien erstellt wurde, wird auf der User Route noch zwischen PUT, PATCH und DELETE unterschieden. Diese beschreiben den Zweck der Anfrage. Alle Anfragentypen außer GET haben auch noch einen “Body”, in dem Daten mitgeschickt werden können. Das liegt daran dass GET-Anfragen die Anfragen sind, die in der Browserzeile gemacht werden. In GET-Anfragen können nur Daten in der Anfrage-URL geschickt werden, z.B. “doorlock.glitch.com?signup=dnoawM9”. Hier wird die GET “/” Route aufgerufen, aber die Information dass “signup” gleich “dnoawM9” ist. Alle anderen Anfragen können zur URL wie vorher erwähnt noch einen Body mitschicken, der dann z.B. aus JSON besteht und Informationen wie einen Anmeldetoken oder eine Emailadresse beinhalten. Dieser sieht dann im Falle der PATCH Route bei “/api/user” so aus:
{
"token": "KEwzD2fKM6AfDhJWu68U",
"uid": "rwX3XcWDkxUnLK4n",
"admin": true
}Hier werden der Token des Anfragenden Nutzers, die UID des Zielnutzers und die neue Rolle von diesem mitgeschickt.
Wie funktioniert die Nutzerverwaltung eigentlich?
Unsere Nutzerverwaltung wird über Google Firebase gehandhabt. Firebase ist ein Googledienst, der Nutzeranmeldung vereinfacht und eigentlich noch viel mehr Services bietet, die wir allerdings nicht verwenden. Wir nutzen Firebase in zwei teilen, zum einen der Admin-SDK, welche als Library auf dem Server läuft, und der Firebase-App, welche auf der Website läuft. Der Grund dafür dass wir die Anmeldung und Nutzerverwaltung nicht auf unserem eigenen Server machen, liegt daran, dass es viel zu einfach ist Anmeldesicherheit falsch zu machen. Im öffentlich verfügbaren Web gibt es mehr Angriffsvektoren als ich hier auflisten kann, und es kommen täglich neue hinzu. Um dagegen überhaupt einen Hauch von Sicherheit zu gewährleisten, lagern wir diesen hochkritischen Aspekt unser Anwendung aus. Das heißt aber nicht dass wir damit keine Arbeit mehr haben. Um mit Firebase zu interagieren müssen wir dessen API benutzen, um Befehle auszuführen. Der Befehl um einen Nutzer zu Registrieren und seine Rolle zu setzen sieht dann so aus:
admin.auth().createUser({
email: req.newUser.email,
emailVerified: true,
password: req.body.password,
displayName: req.newUser.name
})
.then(user => {
admin.auth().setCustomUserClaims(user.uid, {
admin: req.newUser.admin
})
.then(() => res.json({status: 'success'}))
.catch(e => res.status(400).json({error: e}))
})
.catch(e => res.status(400).json({error: e}));Hier fehlt jetzt aber noch der nützlichste Aspekt den wir bei Firebase verwenden, und zwar die Tokenauthentifizierung. Damit kann man sich auf der Website anmelden, dann eine Anfrage bei Firebase mit seinen Anmeldedaten machen, um einen Token zu bekommen, der dann mit jeder Anfrage zum Backend geschickt wird, und dann im Backend wieder mit Firebase verifiziert werden kann. Der ganze Prozess kann so visualisiert werden:
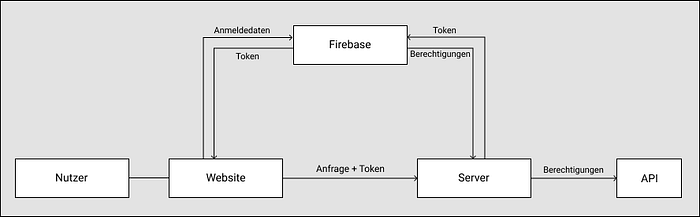
Und dadurch dass wir Express verwenden, können wir dieses Tokenüberprüfen auf der “/api” Ebene machen, ohne das für jeden Pfad einzelnd zu tun. Die “/api/open” Route braucht als einzige keine Adminprivelegien, und die “/api/signup” Route benötigt gar keine Nutzerverifizierung, aus Gründen die ich im folgenden erkläre:
Wie funktioniert das Nutzer hinzufügen?
Wenn wir als Admin einen Nutzer hinzufügen wollen, stoßen wir auf ein größeres Sicherheitsproblem: was machen wir mit dem Passwort des Nutzers? Firebase fordert bei der Nutzererstellung ein Passwort. Setzten wir das Passwort für einen Nutzer automatisch, und brechen dabei alle Hashing- und Sicherheitsregeln, oder gibt es eine andere alternative? Lassen wir jedermann einen Account erstellen und geben diesem dann als Admin einzeln Zugang? Beide Verfahren haben offensichtliche Nachteile, zum einen Sicherheitsrisiken, zum Anderen Spamrisiken. Deshalb haben wir uns für einen andere, kompliziertere Methode entschieden. Um einen Nutzer hinzuzufügen geben wir im Adminbereich den Namen des Nutzers, dessen Email und Rolle ein. Damit machen wir nun eine Anfrage an den Server, welcher dann in einer Datenbank mit diesen Daten einen Eintrag anlegt und noch einen Registrierungstoken hinzufügt. Danach wird an die Emailadresse des neuen Nutzers eine Anmeldungsemail geschickt, die einen Link mit diesem Registrierungstoken enthält. Wenn dieser dann den Link öffnet, hat er nur die Möglichkeit sein Passwort zu setzen:

Dann wird dieses Passwort zusammen mit dem Registrierungstoken wieder an den Server geschickt. Dieser gleicht den Token dann mit dem Datenbankeintrag ab, und erstellt dann den Nutzer in Firebase. Beim Erstellen eines Nutzer können wir diesem mit Firebase noch Attribute hinzufügen, in unserem Fall das Admin-Attribut, welches als Boolean abgespeichert wird. Danach wird der Eintrag in der Datenbank wieder gelöscht, um Doppeltanmeldungen zu verhindern. Der gesamte Vorgang sieht dann ungefähr so aus:

Wie man sehen kann benutzen wir für das Email senden einen Service names SendGrid. Der ermöglicht es uns Emails zu verschicken, ohne sofort im Spamfilter des Nutzers zu landen. Denn Emails senden ist nicht grade einfach, ein Emailserver verwendet mehrere Protokolle, Sicherheitschecks, Registrierung bei bekannten Emailportalen wie z.B. Gmail, Outlook, Yahoo, usw. Außerdem ist es auch schwierig einen Mailserver zu betreiben, aufgrund der hohen Komplexität des Emailprotokolls und dessen Absicherung. Alles in allem ist es schwieriger als gedacht Emails zu verschicken, die verlässlich beim Nutzer ankommen. Wir benutzen SendGrid außerdem noch, da wir über Github Education einen Rabatt bei SendGrid bekommen, wir können damit kostenlos bis zu 15 tausend Emails im Monat schicken. Etwas mehr als wir wahrscheinlich brauchen. Also hoffentlich. Eine Email mit SendGrid zu verschicken geht dank der SendGrid Library für NodeJS relativ einfach:
const msg = {
to: email,
from: 'doorlock@doorlock.malts.me',
subject: 'Registrierung HGO Türschloss',
text: `Du wurdest für das HGO Türschloss freigeschaltet!
Du kannst deine Registrierung unter https://doorlock.glitch.me?signup=${signupToken} abschließen.`,
html: `<h1>Du wurdest für das HGO Türschloss freigeschaltet!</h1>
<h3>Du kannst deine Registrierung <a href="https://doorlock.glitch.me?signup=${signupToken}">hier</a> abschließen</h3>`,
};
// send email to new user
sgMail.send(msg);Hier müssen wir lediglich darauf achten neben der HTML-Version der Email auch eine Textversion bereitzustellen, um auch Emailclients ohne HTML-Unterstützung erreichen zu können.
Wie funktioniert das Loggen?
Um abzuspeichern wer wann die Tür geöffnet hat, benötigen wir eine Datenbank. Dafür verwenden wir SQLite3, eine SQL-Datenbank die ähnlich wie MySQL funktioniert, aber einfach über den NodeJS Packetmanager NPM installiert werden kann, und von einer einzigen Datenbank Datei aus funktioniert. Wir haben ja grade schon die Datenbank zum speichern von Nutzern benutzt. Um in NodeJS mit der Datenbank zu interagieren benutzen wir Sequelize, eine Library um mit SQL-Datenbanken zu kommunizieren. Die einzelnen Table werden im “/model” Ordner aufgelistet, und können jederzeit neu erstellt werden. Der Log Table hat die Felder “createdAt”, “user” und “action”, welche beide als Strings abgespeichert werden. Einen Eintrag erstellt man in Sequelize so:
db.sequelize.sync()
.then(() => db.Log.create({
user: req.firebaseUser.email,
action: 'Tür geöffnet'
}))Dabei wird das createdAt Feld von Sequelize automatisch gesetzt, und sorgt dafür, dass wir später die Einträge chronologisch abrufen können.
Wie funktioniert die Verbindung mit dem Pi genau?
Auf dem Raspberry Pi wird bei jedem Neustart automatisch das clientseitige Script geladen, welches sich per WebSocket mit einem Api-Key bei dem Server anmeldet und so eine durchgehend geöffnete Verbindung schafft. Durch die per Key gesicherte Verbindung ist zum einen sichergestellt, dass der Pi nicht von Aussen angegriffen werden kann, zum anderen umgehen wir das Problem, iServ in die Verbindung mit einzubringen. Drückt nun der Benutzer den öffnen Button, sendet der Server ein Paket an den Client, in dem sich der Benutzername, der Zeitpunkt und die Aufforderung zum Öffnen befindet. Durch die JavaScript Library rpi-gpio ist es uns möglich, direkt einen bestimmten Pin des Raspberry Pi’s anzusteuern. Dieser leitet dann ein Signal durch den Pin, welches dafür sorgt, dass ein Relay kurzzeitig den Stromkreislauf des elektronischen Türschlosses schliesst. Nach 2 Sekunden wird die Verbindung wieder gekappt, sodass der Nutzer genügend Zeit hat, den Raum zu betreten. Der Raspberry Pi ist ausserdem an den Monitor ausserhalb des Computerraumes angeschlossen, auf welchem zu sehen ist, welcher Benutzer die Tür wann geöffnet hat.
Wie benutzen wir Klassen im Server?
NodeJS ist zwar eine Scriptsprache, unterstützt aber trotzdem ein Klassenartiges einbinden von Dateien. Um eine Datei einzubinden verwendet NodeJS den folgenden Syntax:
require('./pfad/zur/datei')
// oder wenn man die eingebundene Datei als Variable speichern will:
let library = require('./pfad/zur/datei')Außerdem ist es möglich, eine Datei in mehreren Scripts gleichzeitig zu importieren, die dann Daten untereinander teilen können:
Die erste Datei ist hier die Beispiel-Lybrary, die von den beiden unteren Dateien importiert wird. Die Library exportiert die Funktionen getText() und setText(newText). Wenn jetzt eine Datei, welche die Library importiert, einen der Funktionen ausführt, werden die Daten global geändert. Das ist besonders praktisch wenn man eine Library in mehreren Orten importiert, die alle die Selben Daten teilen sollen, z.B. für Firebase, dass jedes Script das Firebase benötigt mit der selben Konfiguration initiiert wird, oder dass ich eine geteilte Türschlossklasse habe, die von allen Scripts verwendet werden kann. Und genau das machen wir auch. Im root-Verzeichnis befinden sich die Dateien “lock.js” und “firebase.js”, die in mehreren den Webrouten unter “/routes/api” importiert werden. Die “lock.js” Datei exportiert zwei Funktionen, eine, welche auf eine Websocketverbindung wartet und dann die Adresse des Clients abspeichert und vom Hauptscript importiert wird um die Verbindung weiterzuleiten und eine Funktion welche mit der vorher abgespeicherten Adresse die Tür öffnet und von “/routes/api/open.js” importiert wird. Die Firebase-Klasse exportiert das Firebase-Objekt, welches mit der richtigen Konfiguration initiiert wird und von fast allen Routen importiert wird.
Wo wird der Server gehostet?
Der Server wird über Glitch.com gehostet. Das ist ein kostenloser Hostinganbieter für nichtkommerzielle Anwendungen von den Entwicklern von Trello und StackOverflow, der das Arbeiten am Server erleichtert und uns viele der DevOps-Probleme wie z.B. deployment, uptime, hardening, usw. abnimmt. Zum Einen benötige wir damit keine lokale Entwicklungsumgebung, was beim Arbeiten mit Datenbanken besonders hilfreich ist. Außerdem sorgt Glitch dafür, dass man mit mehreren Leuten gleichzeitig programmieren kann und dabei alle Änderungen direkt live zu sehen sind. Unser Servercode ist übrigens hier öffentlich einsehbar. Als einziges nicht für die Öffentlichkeit sichtbar sind dabei unsere Passwörter für Firebase und die Datenbank. Diese werden beim Start der Anwendung als “environment variables” in den NodeJS Prozess injiziert werden. Dabei bietet Glitch.com eine .env Datei, die nur für uns sichtbar ist. Darin kann man die environment variables wie folgt setzen:
IRGEND_EIN_PASSWORT="kein echtes Passwort"
API_KEY="keinrichtigerkey"Und in NodeJS können diese dann so abgerufen werden:
let passwort = process.env.IRGEND_EIN_PASSWORT;Wie ist das Frontend aufgebaut?
Wie vorher schon erwähnt verwenden wir für das Frontend das Vue.js Framework. Der Hauptgrund dafür ist, dass es Vererbung möglich macht, womit wir Komponenten in verschiedenen Teilen der UI wiederverwenden können, wie z.B. die Modal-Komponente, welche in fast allen Teilen der Anwendung verwendet wird. Jede dieser Komponenten ist eine .vue Datei, welche aus drei Teilen besteht: ähnlich wie eine reguläre HTML-Seite hat jede Komponente einen <html> Bereich, einen <script> Bereich und einen <style> Bereich. Diese sind für jede Komponente eingekapselt, d.h. dass eine Klasse oder Variable, die in einer Komponente deklariert wird, nicht global verfügbar ist, sondern nur für die Instanz der Komponente. Das sorgt dafür dass unerwünschte Datenübertragungen vermieden werden. Hier ist ein Beispiel für die Verwendung von Komponenten auf der Nutzerverwaltungsseite und das Vue-Vererbungsdiagramm des gesamten Frontends.

Wie funktioniert die Navigation zwischen den Seiten?
Jede Seite wird dynamisch von der Hauptkomponente aus geladen. Das System besteht aus zwei Teilen, zum einen einer Variable der Hauptkomponente, die den jetzigen Bildschirm als String speichert, und den einzelnen Komponenten die durch konditionales Rendering geladen werden. Das heißt, dass die Komponente nur im HTML der Hauptseite vorhanden ist, wenn eine Bedingung erfüllt wird. Als Code in Vue.js sieht das dann so aus:
<Users v-if="currScreen === 'Users'"/>Wie man sehen kann bekommt die Users-Komponente hier seinen eigenen HTML-Tag. Außerdem gibt es das v-if Attribut, in dem überprüft wird, ob die Variable “currScreen”, welche in der App.vue Komponente deklariert wird, “Users” entspricht. Falls das der Fall ist, wir eine neue Instanz der User-Komponente erschaffen.
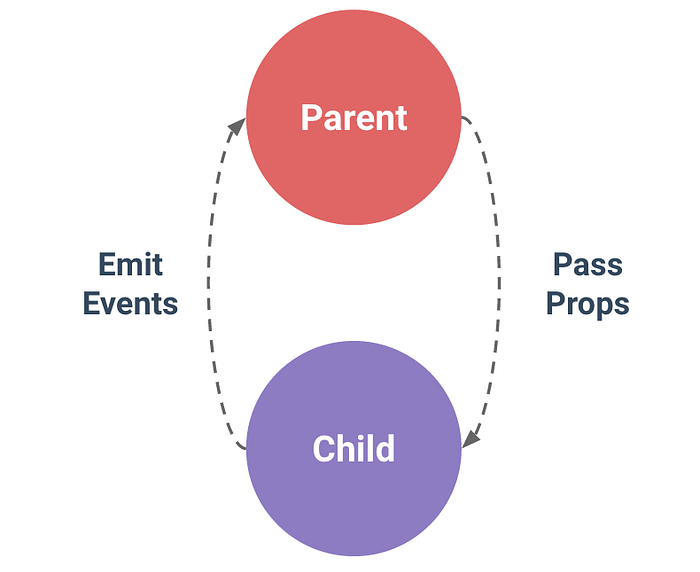
Die Kommunikation zwischen über- und untergeordneten Komponenten funktioniert in Vue dabei über Props und Events. Dabei kann die übergeordnete Komponente der untergeordneten Daten mitgeben, und wenn eine Untergeordnete Komponente Daten vermitteln will, wird ein Event ausgesandt, auf das die übergeordnete Komponente dann reagieren kann oder auch nicht. Diese Events tragen einen Namen und können außerdem Daten mitliefern. Das passiert zum Beispiel bei der Modal-Komponente, welche mit dem anzuzeigenden Text und den Auswahlmöglichkeiten erstellt wird, und dann beim Anclicken einer Auswahlmöglichkeit ein Event mit dem Namen “close” Aussendet, welche als Daten die Auswahl mitliefert.
Wie funktionieren die einzelnen Seiten: Anmeldung

Die Anmeldeseite macht hauptsächlich drei Dinge: Sie initiiert Firebase, erlaubt dem Nutzer sich anzumelden, und leitet den Nutzer weiter falls er sich bereit angemeldet hat. Wie auch in NodeJS kann man in Vue Pakete importieren, und genau dass machen wir auch im Frontend. Alle Seiten die Firebase brauchen, importieren es, aber wir brauchen es nur ein mal initiieren. Praktisch ist dabei auch, dass man aus dem Firebase Paket nur einzelne Teile importieren kann, wir benötigen nämlich nur den Authentifizierungsteil von Firebase. Sobald wir Firebase initiiert haben, fügen wir einen sogenannten “Event Listener” an das “onAuthStateChanged” Event an. Jedes mal wenn sich ein Nutzer an oder abmeldet wird, wird eine von uns vorgegebene Methode ausgeführt. Das hat den Grund, dass der Nutzer angemeldet bleiben kann, obwohl er die Seite geschlossen hat. Öffnet er sie dann wieder, wird dieses Event ausgelöst ohne dass der Nutzer seine Anmeldedaten erneut eingeben muss. Es wird aber auch dann ausgelöst wenn sich der Nutzer grade Angemeldet hat, also Nutzen wir diesen Event Listener um auf einen der Bildschirme zu wecheln. Dabei wird unterschieden ob der Nutzer ein Admin ist oder nicht, denn nur falls der Nutzer Administratorprivelegien hat, wird ihm auch die Navigationsleiste am unteren Bildschirmrand angezeigt.
Wie funktionieren die einzelnen Seiten: Türkontrolle
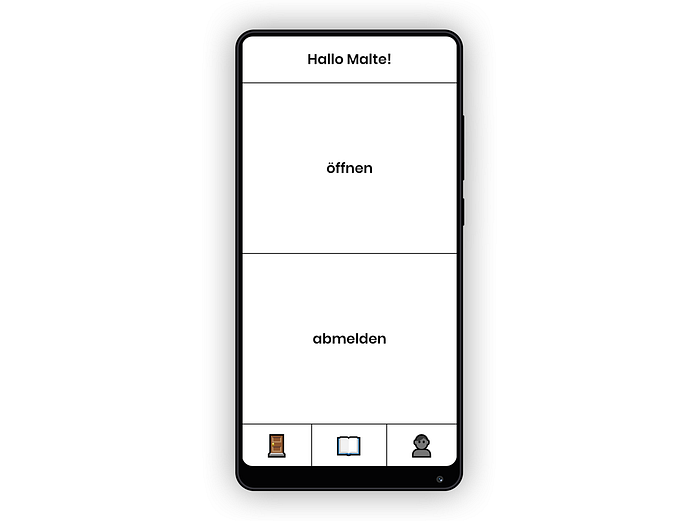
Die Türkontrolle ist noch eines der simpleren Komponenten. Es wird initiiert mit dem Namen des Nutzers, der dann am oberen Bildschirmrand angezeigt wird. Firebase Auth wird auch hier importiert, und der “abmelden” Button führt die Firebase Funktion zum abmelden aus und schickt dann das Event zum Anzeigen des Anmeldebildschirms an. Der “öffnen” Button holt sich dann erste den Nutzertoken von Firebase, und sendet den dann mithilfe der fetch()Funktion an den Server. Die fetch()Funktion ist in eigentlich jedem Browser automatisch integriert und ermöglich ein einfaches Erstellen von Webanfragen. Das sieht dann im Falle des Türöffnens so aus:
fetch('/api/open', {
method: "POST",
body: JSON.stringify({
token: idToken
}),
headers: {
"Content-Type": "application/json"
}
})die fetch()Funktion nimmt dabei zwei Variablen an, zuerst die Route, auf der die Anfrage ausgeführt wird, und dann ein Objekt dass die Art und Daten der Anfrage beschreibt. Unsere Route und Methode können wir einfach aus unserem API-Diagramm ablesen, der Body besteht hier aus einem Objekt dass mithilfe der JSON.stringify()Methode als String abgeschickt wird und nicht als Binärstream, damit der Server die Anfrage leichter verarbeiten kann. Als nächstes setzten wir noch die Anfrageheader, die in unserem Fall sagen dass es sich bei der Anfrage im body um JSON(JavaScript Object Notation)-Daten handelt. Die fetch() Funktion ist ein “Promise”, das heißt dass an den Funktionsaufruf .then() und .catch() Blöcke gehangen werden können, die alle nach dem Fertigwerden der fetch()Funktion ausgeführt werden. Das liegt daran, dass JavaScript eine Asynchrone Sprache ist, und damit dass man mit .then() erst weiter macht, wenn die Anfrage durchgekommen ist. Damit kann jeder andere JavaScript code trotzdem ausgeführt werden, auch wenn er normalerweise mit dem fortfahren warten müsste aufgrund der nicht abgeschlossenen fetch()Funktion. Da JavaScript dadurch auch nicht den Renderprozess blockiert, kann der Nutzer in der Zeit in der noch eine Anfrage an den Server im Gange ist auf z.B. die Logs-Seite navigieren.
Wie funktionieren die einzelnen Seiten: Logs
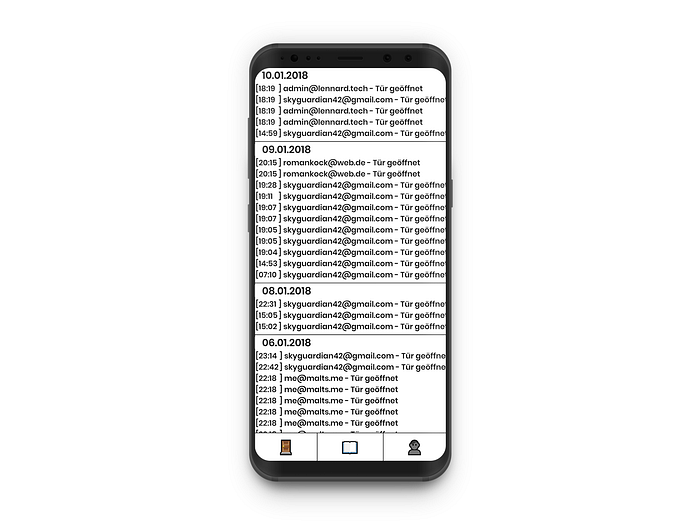
Die Logseite ist schon etwas komplizierter. Die Logseite wurde am Anfang des Projekts als leere Komponente initiiert und erst danach wurde eine Anfrage an den Server geschickt. Und da jedes mal wenn die Seite gewechselt wurde, wurde die Komponente mit leeren Daten gezeigt, bis die ersten Ergebnisse geladen wurden. Das hat für unnötige Wartezeiten und eine langsamere Interaktion beim Nutzer gesorgt. Um dem entgegenzuwirken haben wir einen caching-Mechanismus in das Programm eingebaut, das falls die Seite zum ersten mal aufgerufen wurde, die erste Antwort vom Server an die Hauptkomponente schickt. Falls die Log Seite dann ein weiteres mal geöffnet wird, kann sie mit diesen Daten initiiert werden, und es gibt keine leeren Seiten mehr. Eine Anfrage an den Server wird trotzdem gestellt, im Falle dass seit dem letzten Seitenaufruf neu Logeinträge dazugekommen sind. Diese überschreiben dann die Daten mit denen die Komponente initiiert wurde.
Was meinte ich eigentlich grade mit der “ersten” Anfrage an den Server? Es macht bei einem solchen System keinen Sinn alle Logeinträge die je getätigt wurden zu laden, vor allem da es hoffentlich mehrere Jahre halten soll und dabei möglicherweise tausende von Logeinträgen gespeichert werden. Stattdessen haben wir ein System implementiert, das die Einträge “lazy loaded”, das heißt, dass jeweils nur eine bestimmte Anzahl von Logeinträgen gleichzeitig vom Server angefordert werden. Das System dahinter ist eigentlich relativ simpel: Die Website nimmt jeweils den ältesten Eintrag, und stellt dann eine Anfrage an den Server mit diesem Datum. Der Server kann dann mithilfe einer SQL-Anfrage in der Datenbank nach Einträgen suchen die älter sind als das angeforderte Datum und dann eine bestimmte Anzahl an Einträgen ausgibt. Diese wird dann zurück an die Website geschickt, die die Resultate dann filtert und anzeigt. Falls die Anzahl der angekommenen Ergebnisse kleiner ist als die der Angeforderten, sind keine älteren Einträge in der Datenbank mehr vorhanden ,ansonsten sind noch Einträge vorhanden und es wird ein “mehr Einträge laden” Button angezeigt. Die SQL-Anfrage sieht auf der Serverseite dann so aus:
db.Log.findAll({
limit: 35,
where:{
createdAt: {
[db.Sequelize.Op.lt]: offset ? offset : db.Sequelize.NOW()
}
},
order: [ ['createdAt', 'DESC'] ],
attributes: ['createdAt', 'user', 'action']
})
.then(logs => res.json(logs))Wir sortieren die Einträge absteigend nach “createdAt”, aber nur wo “createdAt” älter ist als die offset Variable, und falls die Variable nicht vorhanden ist, die aktuelle Zeit. Und wir setzten das “limit” der Anfragen auf 35. Das sind genug Einträge um auf fast allen Geräten den Bildschirm zu füllen. Die Ergebnisse aus diesem Datenbankaufruf werden dann wieder asynchron mithilfe von .then()an den Anfragesteller geschickt.
Wie grade angesprochen sind diese Einträge noch nicht wie auf der Website nach Tagen kategorisiert. Das machen wir lokal auf der Website, mithilfe der “computed” Funktionen in Vue.js. Das sind Funktionen die einen Wert zurückgeben wenn sie Ausgeführt werden, genau wie in z.B. Java. Die computed-Funktionen werden aber einer Variable zugewiesen und jedes mal ausgeführt wenn sich diese Variable ändert. In unserem Fall haben wir ein Array aus Logeinträgen, an das bei jeder Request die Ergebnisse angehangen werden, ähnlich wie in dynamischen Arrays in Java. Unsere computed Methode sortiert dann die Einträge indem sie jedem Eintrag in den unsortierten Logs durchgeht, und dabei ein zweites Array anlegt, welches aus Objekten besteht, die zum Einen das Datum, und zum Anderen ein weiteres Array aus den korrespondierenden Logeinträgen enthält. Diese sortierten Einträge werden dann bei jeder Änderung automatisch angezeigt.

Außerdem haben wir einen Ladeindikator eingebaut, um die gefühlte Ladezeit zu verkürzen. Animiert nur mit CSS und bestehend aus nur zwei HTML Elementen ist dieser natürlich auch eine Vue Komponente.
Wie funktionieren die einzelnen Seiten: Nutzerverwaltung
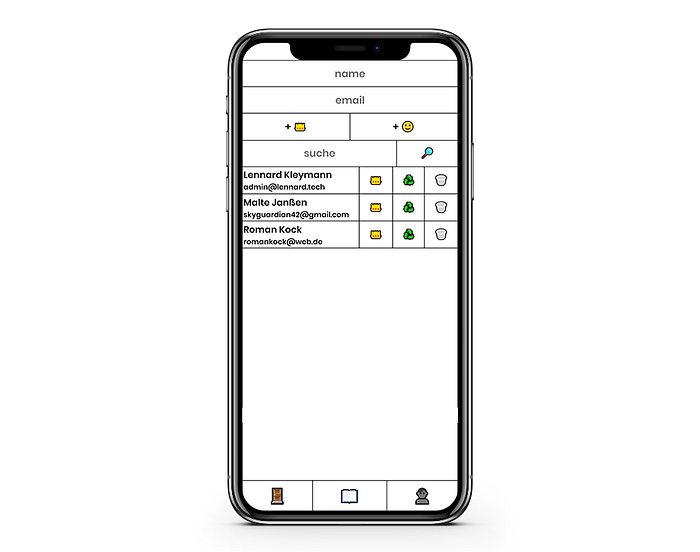
Die Nutzerverwaltung besteht wie bereits aus mehreren Komponenten, zum einen der Liste aller Nutzer, zum anderen das Interface zum Hinzufügen eines Nutzers. Das Hinzufügen eines Nutzers ist einfach gehalten, der Admin gibt die Email und den Namen des Nutzers an, wählt dann den Button mit +👑 aus, um einen Admin hinzuzufügen, oder +🙂 um einen regulären Nutzer hinzuzufügen. Das wird dann nachdem erhalten des eigenen Tokens an den Server gesendet, der sich um den Rest kümmert. Die Liste der Nutzer besteht aus “UserListing” Komponenten, die für jedes Element in einem Array dargestellt werden. Ähnlich wie im Logsbildschirm werden hier die Ergebnisse der ersten Serveranfrage in der Hauptkomponente gecached. Die UserListing-Komponente wird mit vier Variablen initiiert: dem Name, der Email, der Rolle und der UID des Nutzers.
Die erste Funktion ist das ändern der Rolle eines Nutzers. Dafür wird wieder eine Anfrage an den Server mit dem eigenen Token, der neuen Rolle und der UID des Nutzers gestellt. Die UID steht dabei für den “Unique Identifier” des Nutzers, mit welchem Firebase auf den Eintrag des Nutzers zugreift. Auf der Serverseite kann nun mit der setCustomUserClaims() Methode von Firebase der Wert Admin, welcher an das Nutzerobjekt in Firebase angehängt ist, auf den gewünschten Wert gesetzt werden.
Die zweite Funktion ist das Passwort zurücksetzten. Gekennzeichnet durch den ♻️ Button, kann man die Passwortzurücksetzung in Firebase direkt von der Website aus auslösen. Das geht mit der sendPasswordResetEmail() Funktion, welche lediglich die Email des gewünschten Nutzers benötigt.

Die dritte und letzte Funktion ist das Löschen eines Nutzers. Dabei handelt es sich zwar auch um eine Serveranfrage, aber die Aktion ist destruktiv und irreversibel, weshalb ein aus Versehenes auslösen um jeden Fall vermieden werden muss, besonders weil sich der Button direkt neben dem Passwort zurücksetzten Button befindet, welcher höchst wahrscheinlich am meisten verwendet wird. Aus diesem Grund importiert jede UserListing-Komponente die Modal-Komponente, um den Nutzer zu warnen und die Aktion zu bestätigen. Nach der Bestätigung macht die Website dann eine Anfrage an den Server mit dem eigenen Token und der UID des Zielnutzers, und löscht dann den Eintrag des gelöschten Nutzers aus dem Array der Übergeordneten User-Komponente. Dadurch muss die Nutzerliste nicht neu geladen werden und der Nutzer hat keine Wartezeit zwischen Aktionen.
Wie sieht die Seite denn auf Computern aus?
Bei der Gestaltung der Website haben wir mit dem Prinzip des “Mobile First Design” gearbeitet. Dabei gestaltet man die Website zuerst für kleinere Displays wie Smartphones oder Tablets, es einfacher ist, ein Design, das für ein kleineres Display gestaltet hat, und somit meist weniger Content auf einmal anzeigt, auf einen größeren Bereich aufzuteilen, als zu versuchen, eine für große Displays erstellte Seite auf die Größe eines Smartphones zu quetschen. Außerdem gehen wir davon aus dass unsere Website fast ausschließlich von Mobilgeräten aus verwendet wird, da wahrscheinlich niemand seinen Laptop mitnimmt um ein Türschloss zu öffnen. Trotzdem gibt es auf der Websites kleinere Anpassungen für größere Bildschirme. CSS bietet mehrere Wege dafür, diese Anpassungen vorzunehmen. Eine davon ist die Einheit rem(root element), welche sich auf das font-sizeAttribut des <html> Elements. Diese Einheit kann dann in CSS z.B. anstatt der px Einheit verwendet werden. Das wird aber erst richtig nützlich, wenn wir ein zweites Feature von CSS verwenden: Media Queries. Mit diesen kann man basierend auf z.B. der Fenstergröße oder Orientierung dynamisch CSS Attribute setzen. Das verwende ich zum einen zum Vergrößern der Schriftgröße, aber auch zum ändern des Layouts. Um die Buttons auf der öffnen-Seite auf Displays in der “landscape” Orientierung nebeneinander anzuzeigen, kann man Media Queries so verwenden:
@media (orientation: landscape) {
.klasse {
flex-direction: column;
}
}Der Unterschied sieht dann so aus:

Der Log-Bildschirm wurde auch verändert, die Logeinträge sind auf Desktops mittig zentriert, um eine große leere Fläche am rechten Bildschirmrand zu vermeiden.
Zusammenfassung
Das gesamte Projekt hat sich am Ende als komplizierter als gedacht herausgestellt. Was mit einem einfachen Knopf zum Türöffnen begann ist zu dieser Anwendung herangewachsen. Viele der implementierten Funktionen waren am Anfang nicht eingeplant, was zum einen an unser fehlenden Erfahrung im Erstellen von komplexeren Anwendungen, und zum anderen damit dass sich Probleme oft dort auftun wo man sie am wenigsten erwartet. Alles in Allem hat sich die Erfahrung aber auf jeden Fall gelohnt, und die Erfahrung die wir dabei gesammelt haben wird sich hoffentlich irgendwann mal als nützlich erweisen. Der Code ist in mehrere Git Repositories aufgeteilt und sind hier zu finden:
- Der Client Code für den RaspberryPi — Github
- Der Server Code — Github — Glitch.com
- Der Frontend Code — Github Sourcecode — Kompilierte Dateien(mit mehr Commits)
- Lennard und Malte
